
AI Exposure and CTEM: The Next Frontier of External Risk
Prepared by: Sudhanshu Chauhan 🔗 (Director, RedHunt Labs) and Devang Solanki 🔗 (Security Researcher, RedHunt Labs)
There is a loop in cybersecurity. A new technology enters the enterprise. Adoption moves faster than governance. Security teams hear about it during incident response instead of during planning. And the exposure window, that gap between deployment and visibility, gets exploited before anyone realizes it even existed.
We saw it with open cloud storage buckets. We saw it with exposed Kubernetes dashboards. And now, we are watching it unfold again with AI.
The real question is no longer “Are we using AI?” Every organization is. The question that should make security teams uncomfortable is this: What components of AI are running that you are not aware of ?
Table of Contents
- The Pattern We Have Seen Before
- Understanding AI Exposure, Layer by Layer
- The Inference Layer: Where Models Run
- Agent & Orchestration: Where AI Gets Agency
- Data & Memory Layer: Where Organizational Knowledge Lives
- ML Engineering Layer: Where Models Are Built
- Gateway and Telemetry Layer: Where Models Are Governed
- The Artifact and Plugin Layer: Where Capabilities Are Distributed
- The Public Interaction Layer: Where Conversations Become Data
- Identity & Access Layer: The Keys to the Kingdom
- Shadow / Misc: Where Demos Become Permanent
- Why Traditional CTEM Falls Short
- What AI Aware CTEM Needs to Look Like
- The Governance Dimension
- How We Are Approaching This at RedHunt Labs
- What Comes Next
Useful Links:
AI Exposure Cheatsheet GitHub Repo: https://github.com/redhuntlabs/awesome-ai-exposure-cheatsheet
“No CVE for That” NULLCON 2026 Presentation Slides: https://www.slideshare.net/slideshow/no-cve-for-that-ai-exposures-explained/286453463
Research Dashboard: https://research.redhuntlabs.com/
Open Source Tools: https://redhuntlabs.com/open-source-free-tools/
More Whitepapers: https://redhuntlabs.com/whitepapers/
The Pattern We Have Seen Before
If you have been in security long enough, this feels familiar. Rapid adoption. Limited visibility. A quiet assumption that something internal must be safe. And then the uncomfortable discovery that it was exposed the entire time. One such example: https://www.wiz.io/blog/exposed-moltbook-database-reveals-millions-of-api-keys.
At RedHunt Labs, we have seen this pattern repeatedly through our Project Resonance 🔗 research. Thousands of misconfigured cloud buckets are leaking secrets. Kubernetes clusters with admin consoles exposed to the internet. And most recently, in Wave 15, we found thousands of secrets leaking through vibe-coded websites. Explore more about that from our wave 15 blog 🔗

People are adopting AI left, right, and center. Along with that, the data going to these components is ending up in public exposure.
This adoption is driven by non-technical users building production systems. Security posture is trailing behind. AI is following the same trajectory cloud and containers did, except it is moving faster, and the data it touches is often far more sensitive.
Let’s break this down.
Understanding AI Exposure, Layer by Layer
AI exposure is not abstract. It is layered, and those layers compound. A weakness at one layer can amplify risk at another.
The Inference Layer: Where Models Run
This is the foundation. Tools like Ollama, vLLM, llama.cpp, and HuggingFace TGI make self-hosting LLM models simple and fast. Powerful by design, but often exposed by default.
Take Ollama 🔗 as an example. Out of the box, it binds to all network interfaces without authentication. A simple GET request confirms it is running. Calling /api/tags lists loaded models. Calling /api/generate allows anyone to run inference. That is not a misconfiguration in the traditional sense. It is simply how it ships.
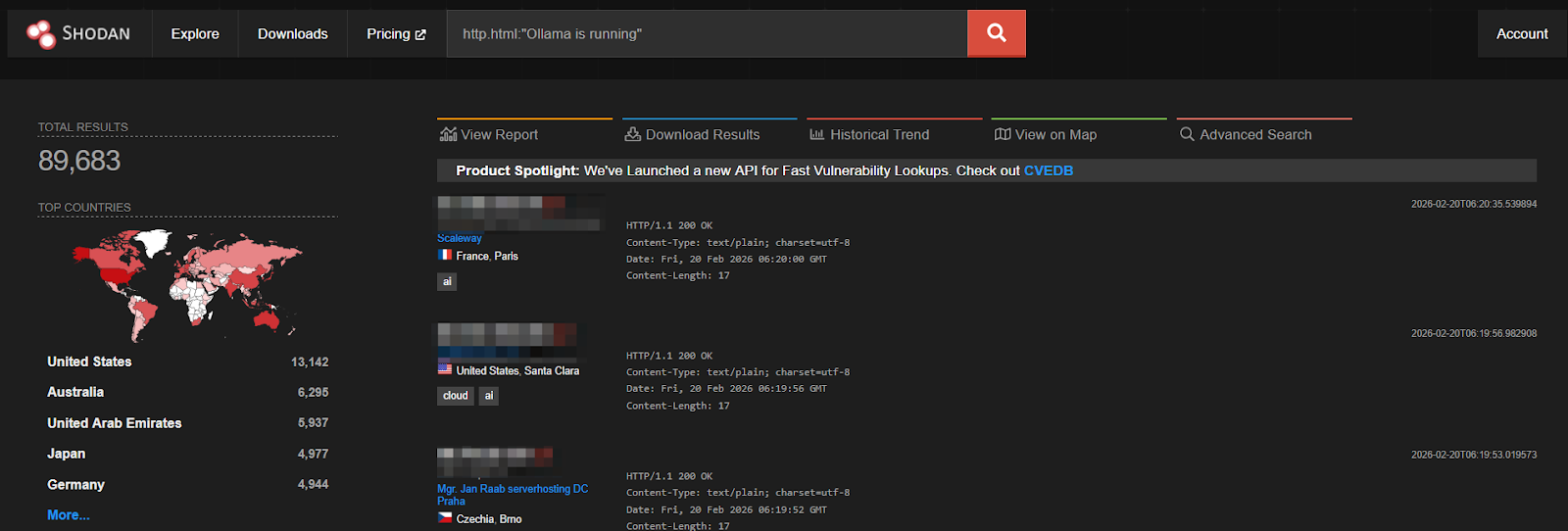
In early 2025, a blog from Cisco 🔗 highlighted just over 1,100 exposed Ollama instances discovered via Shodan scans, with nearly 20 percent running models accessible without authentication.
Based on recent scan data reflected in current Shodan screenshots, that figure has grown nearly 80 times, with close to 90,000 instances now publicly reachable. The jump makes one thing clear: AI infrastructure is being adopted and deployed at a pace that far outstrips security hygiene.
The risk goes beyond unauthorized usage. Exposed inference servers carry known CVEs, including remote code execution. If they are not in your asset inventory, they are not being patched. There is also the quieter risk of model extraction and IP theft. Through timing analysis or API probing, attackers can infer model behavior and internal structure without touching the filesystem. For proprietary models, that is competitive loss, not just exposure.
Agent & Orchestration: Where AI Gets Agency
Agent frameworks, workflow engines, and chat interfaces sit above the model and orchestrate how it interacts with tools, APIs, and external systems. Platforms such as Open WebUI, LangGraph-based agents, and personal agent frameworks like OpenClaw allow a model to read files, run commands, call APIs, and automate tasks through a single conversational interface. This layer is where AI moves from answering questions to performing real actions inside systems.
The risk comes from how these interfaces are deployed. Many chat UIs ship with weak authentication or default credentials, and some are exposed directly to the internet. When that happens, attackers can gain access to stored conversations, prompts, and configuration settings. Chat histories often contain sensitive context such as API keys, internal prompts, or personally identifiable information, making them valuable targets for large-scale data harvesting.
Plugins and tool integrations add another attack path. If an agent is connected to internal services, databases, or automation tools, a compromised plugin or malicious prompt can cause the agent to call those services on behalf of the attacker. Instead of exploiting infrastructure directly, attackers manipulate the orchestration layer that already has trusted access.
The rapid growth of OpenClaw 🔗, an open source AI agent with over 100,000 GitHub stars and millions of weekly users, illustrates how quickly this ecosystem is expanding. Researchers discovered a high-severity flaw that allowed attackers to hijack the agent through its WebSocket interface, further demonstrating how exposed agent control layers can lead to full system compromise.
The result is a shift in the threat model. Compromising the orchestration layer does not just expose data. It gives attackers control over an autonomous system that already has access to tools, credentials, and internal services.
Data & Memory Layer: Where Organizational Knowledge Lives
Vector databases such as Qdrant, Weaviate, Milvus, and Chroma power RAG systems. They store embeddings derived from internal documents and proprietary data.
Embeddings are often dismissed as harmless numbers. They are not. In many cases, text can be reconstructed with surprising accuracy.
An exposed vector database can enumerate collections instantly. What appears to be a simple service may represent a compressed version of your internal knowledge base. Recent CVEs in platforms like Weaviate and AnythingLLM highlight how quickly this ecosystem is evolving and how uneven its security maturity still is.
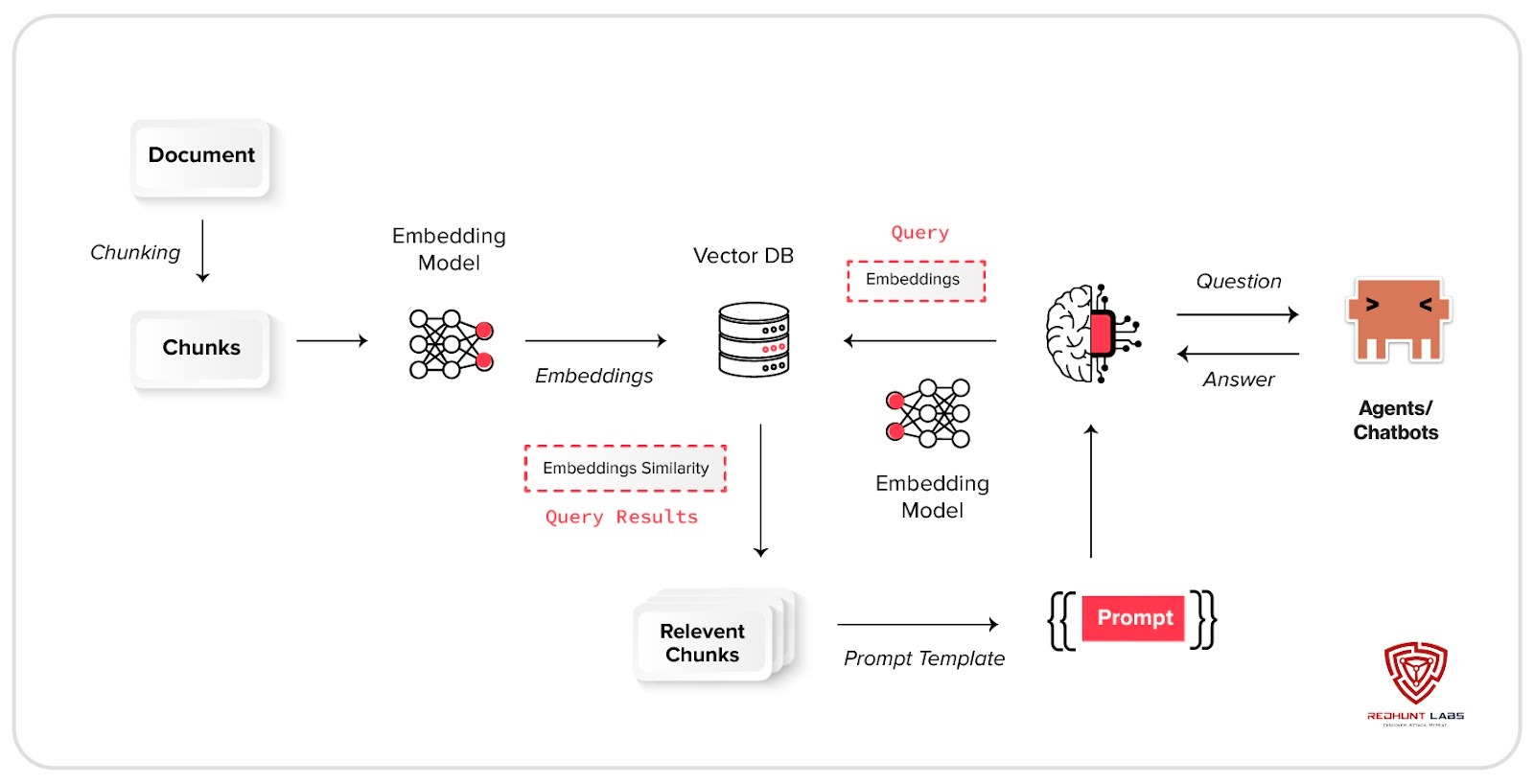
When a vector database is exposed, it is not just an open port. It is potentially your internal knowledge, searchable from the internet.
ML Engineering Layer: Where Models Are Built
Behind every production AI system sits an engineering stack responsible for training, testing, and deploying models. MLOps platforms, experiment tracking systems, and model registries form the backbone of this layer. They help teams iterate quickly by managing datasets, model artifacts, training runs, and deployment workflows.
However, this convenience introduces a new category of risk. Exposed experiment dashboards, publicly accessible model registries, unsecured datasets, or poorly protected CI/CD pipelines can allow attackers to tamper with models, steal proprietary artifacts, or manipulate training configurations. In the worst cases, this can enable model poisoning attacks or allow adversaries to inject malicious components into the ML pipeline.
The impact goes far beyond simple data exposure. Compromising this layer can undermine the integrity, availability, and confidentiality of the models themselves. Without strong authentication controls, proper network segmentation, and continuous monitoring, organizations risk losing visibility and control over how their AI systems are built and maintained.
Gateway and Telemetry Layer: Where Models Are Governed
As organizations adopt multiple AI providers and models, a governance layer often sits in front of them. AI gateways and observability systems act as control points that manage how applications interact with models. These systems handle request routing, API key management, rate limiting, logging, and usage monitoring.
Tools such as LiteLLM act as centralized gateways that sit between applications and model providers, allowing teams to enforce policies and manage traffic across different models from a single interface. While this architecture simplifies operations, it also creates a critical control surface.
If these gateways or telemetry systems are exposed or weakly secured, they become attractive targets. Attackers may abuse stored tokens, manipulate prompts passing through the gateway, extract sensitive responses, or generate large volumes of traffic to inflate usage costs. Because the traffic appears legitimate, traditional security tools may struggle to detect abuse.
In practice, this layer functions as the control plane of the AI stack. If it is compromised, attackers gain visibility and influence over how models are used across the organization.
The Artifact and Plugin Layer: Where Capabilities Are Distributed
Modern AI systems rarely operate in isolation. The Model Context Protocol, or MCP, connects large language models and agents to external tools, databases, APIs, and even code execution environments. If an MCP server is exposed without strong authentication and authorization, it can reveal what tools an agent can access and potentially allow misuse of those resources. Research has shown that weaknesses in these orchestration layers can manipulate how agents interpret tool instructions or trigger unintended actions. The model is no longer just generating text. It is interacting with real systems.
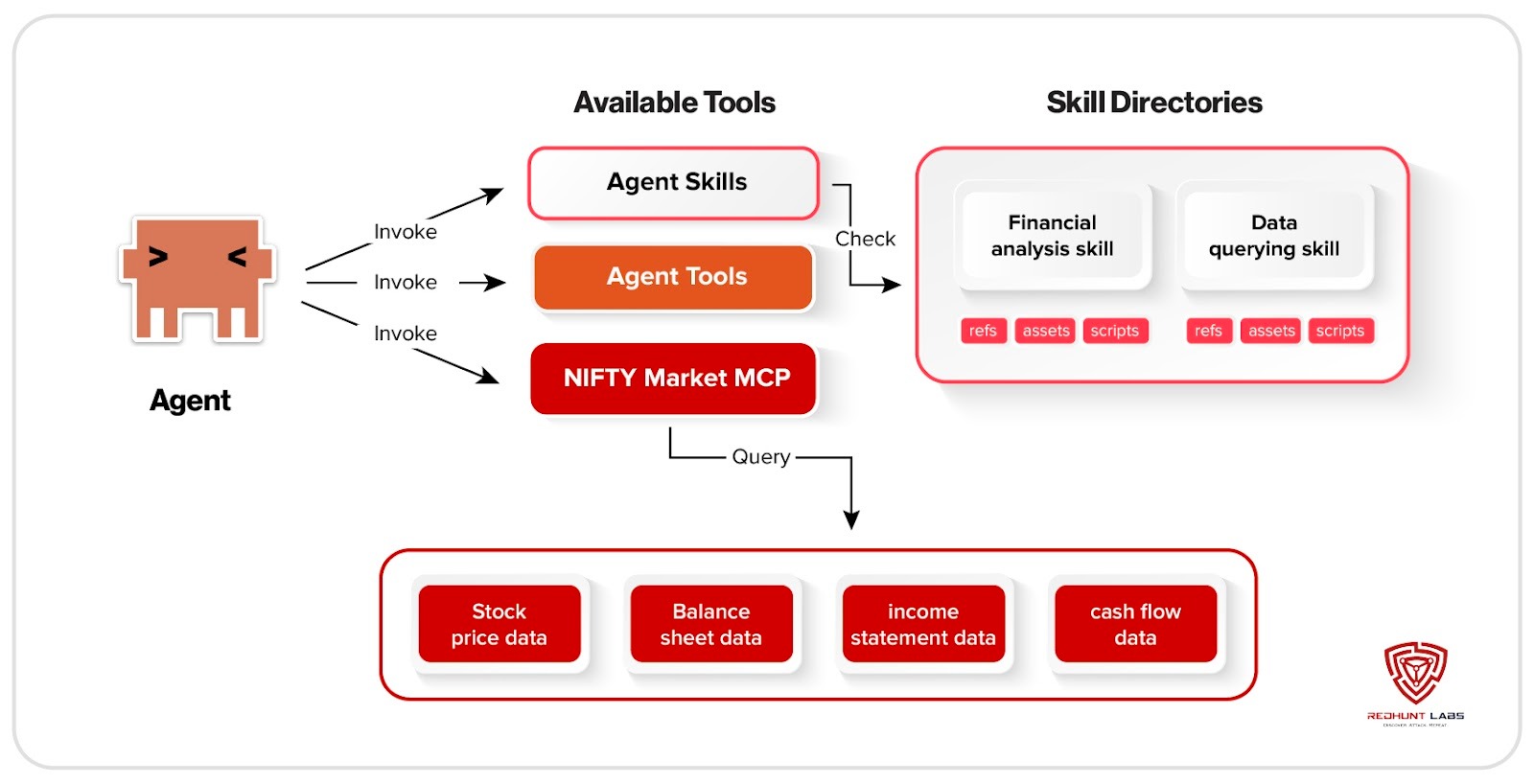
That orchestration layer expands further through agent skills and plugins. These are modular capability packages that define how an agent uses tools and performs tasks. They package instructions, tool definitions, and workflow logic that agents can invoke automatically. While they improve structure and automation, they operate within the same permissions granted to the agent. A malicious or poorly reviewed skill can abuse those privileges to steal credentials, run unauthorized commands, or extract sensitive data.
Beyond plugins and skills, modern AI development also relies heavily on shared artifacts. Platforms such as Hugging Face 🔗 host millions of models, datasets, and training artifacts that developers download directly into their environments. These artifacts often include serialized model files, configuration scripts, and custom code required for loading or running the model. If a malicious model, dataset, or plugin is introduced into this ecosystem, it can execute code during loading, manipulate outputs, or introduce hidden backdoors into downstream systems.
This creates a new kind of supply chain risk for AI. Instead of only trusting application dependencies, organizations now implicitly trust models, datasets, tool definitions, and plugins sourced from public hubs and registries. When these artifacts are integrated without proper verification or sandboxing, they can quietly become part of production workflows.
In practice, this layer acts as the distribution network for AI capabilities. It accelerates development, but it also introduces a new pathway for compromise if artifacts, plugins, or skills are not carefully validated and monitored.
The Public Interaction Layer: Where Conversations Become Data
Modern AI platforms allow users to share conversations through public links, similar to the “Share chat” feature in tools like ChatGPT, Claude, and Gemini. These links create a web view of the entire conversation, including both prompts and responses, which anyone with the URL can access.
The risk appears when these shared sessions contain sensitive information. Prompts often include API keys, internal documentation, system prompts, or proprietary workflows. Once a conversation is shared, the entire exchange becomes visible through the link and can be copied or redistributed by anyone who accesses it.
In some cases, shared AI conversations have even appeared in search engines after users enabled discoverability, exposing prompts and responses publicly on the web. Even when platforms disable indexing, shared links can still be passed around, scraped, archived, or cached by third parties, making the exposure difficult to fully revoke.
What looks like a simple collaboration feature can therefore become part of the external attack surface. A single shared link can expose prompts, sensitive data, internal instructions, and conversation history that organizations never intended to make public.
Identity & Access Layer: The Keys to the Kingdom
AI has introduced a new category of credentials. OpenAI keys. Anthropic keys. HuggingFace tokens. Replicate tokens. Each follows predictable patterns, and each regularly appears in public repositories and client-side code.
Over the past week, our automated GitHub scanner, which monitors all newly published commits, detected 2,568 AI-related API keys exposed in public GitHub repositories. The graph below shows a breakdown of the most frequently identified key types.
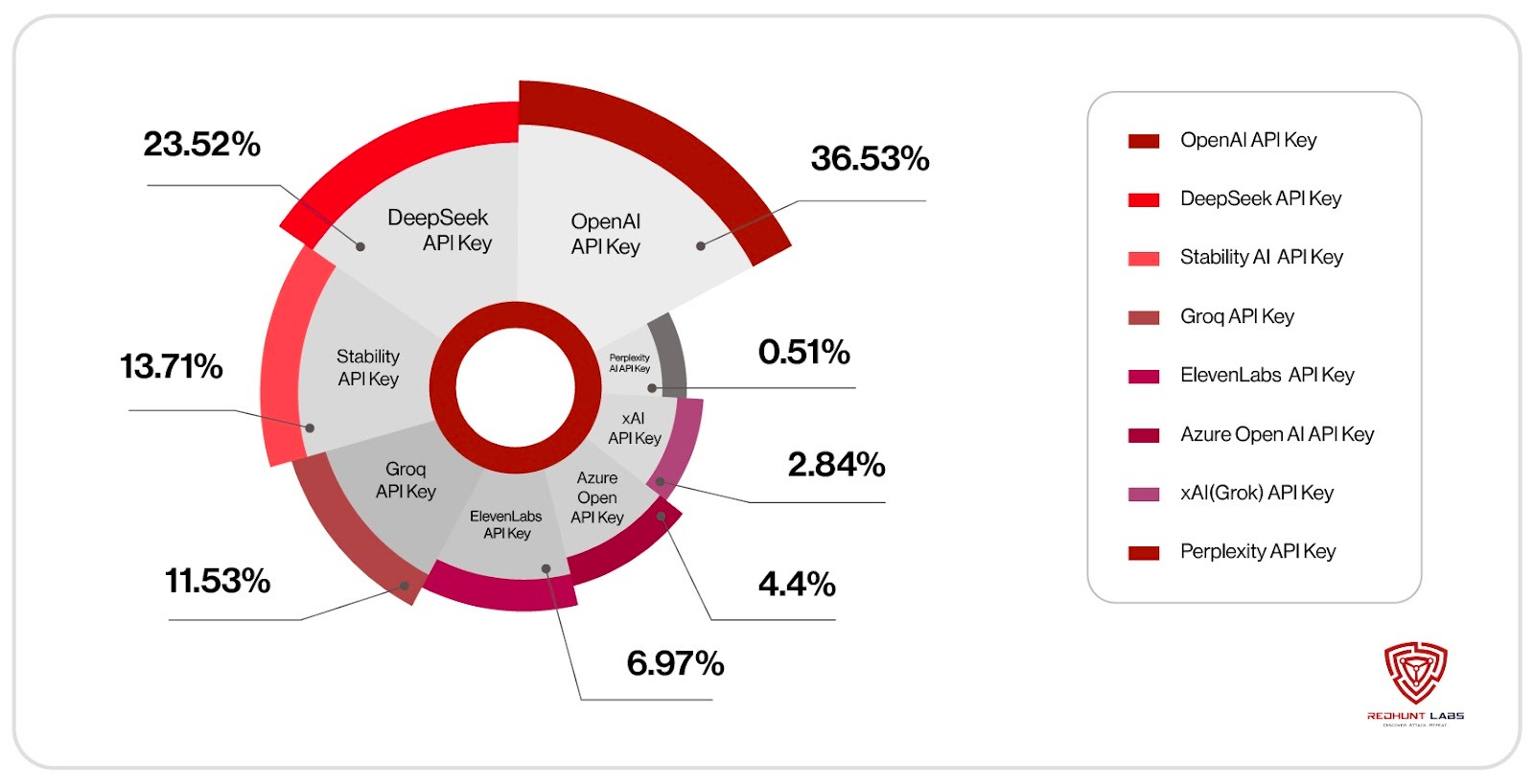
In early 2025, an xAI developer leaked an API key 🔗 on GitHub that exposed private LLMs used internally by SpaceX, Tesla, and X. The key remained active for weeks.
A leaked AI key is not just a billing concern. It can expose conversation history, fine-tuned models, and internal datasets.
On the supply chain side, typosquatted AI packages on PyPI and npm are already being used as attack vectors. Serialized model files can execute code during loading. The AI supply chain is maturing quickly, but security controls are still uneven.
Shadow / Misc: Where Demos Become Permanent
Gradio, Streamlit, and Open WebUI make it effortless to wrap a model in a web interface. They are ideal for demos, internal experiments, and quick prototypes. They were never meant to sit on the open internet.
Yet they frequently do.
A developer spins up a demo on a cloud VM to show a team. Port 7860 is open. No authentication. What was meant to last for 30 minutes remains accessible for months.
In 2025, multiple critical vulnerabilities were disclosed in Gradio, including unauthenticated file access issues. Combine that with backend connections to internal APIs or sensitive data, and you have a pivot point into deeper systems.
AI agents are no longer just assisting developers; they generate, modify, and deploy production‑ready code. Tools like Lovable, v0, Claude Code, and Replit Ghostwriter let users describe an application in plain language and get a working frontend, backend, database integration, and deployment pipeline within minutes. The barrier to shipping software has collapsed.
Speed comes with risk. As we cited earlier in this blog, during our Wave 15 research 🔗, roughly 130,000 websites built across 13 popular vibe coding platforms were scanned. One in five exposed at least one secret. About 25,000 unique secrets were found, many of them AI platform credentials! Google Gemini API keys accounted for nearly three-quarters of these exposures, followed by OpenAI and ElevenLabs. These were not sophisticated attacks; they were direct exposures in publicly accessible applications generated at speed.
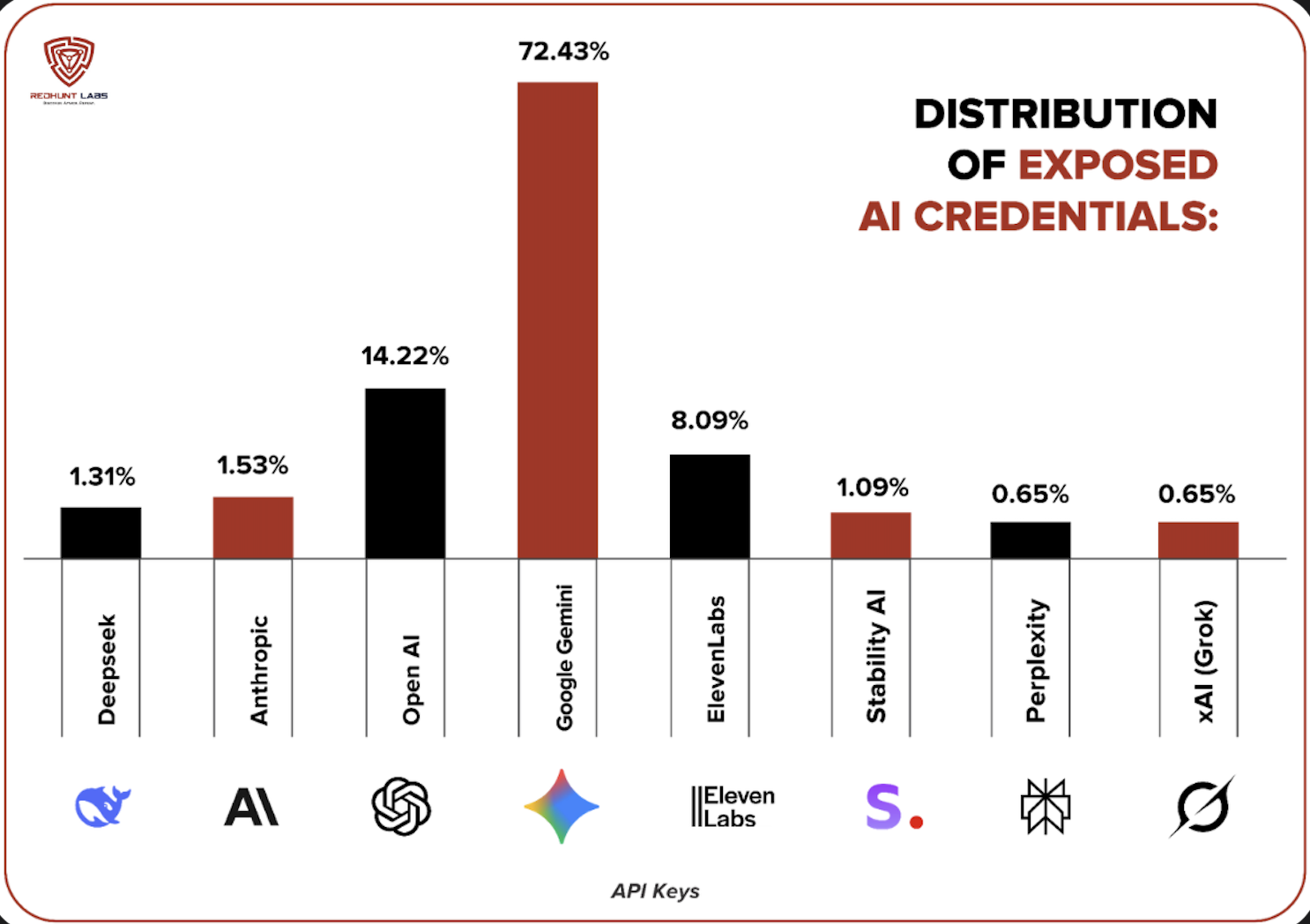
The risk extends beyond leaked credentials. LLM‑generated code often introduces insecure patterns: missing authorization checks, weak session handling, unsafe system calls, and improper authentication flows. The combination of rapid generation, instant deployment, and uneven security practices turns experimentation into production and production into exposure.
Security teams now face a new reality: AI accelerates both software creation and the potential for widespread vulnerabilities.
Why Traditional CTEM Falls Short
Continuous Threat Exposure Management works well for traditional infrastructure. Web applications. Cloud storage. Network services.
AI changes the assumptions.
Port scanning finds open ports. It does not understand AI services. An Ollama instance looks like generic HTTP traffic unless you probe it correctly. Banner grabbing is insufficient when many AI services sit behind common frameworks.
More importantly, traditional CTEM lacks AI context. We explored this gap in detail during our research talk “No CVE for That” at Nullcon Goa 2026, checkout our event presentation 🔗 for more details. It sees an HTTP endpoint. It does not see loaded models, connected tools, or linked data stores.
An exposed S3 bucket leaks files. An exposed AI agent with tool access can read files, query databases, execute actions, and respond to natural language prompts that require minimal technical skill to exploit. The blast radius is fundamentally different.
What AI Aware CTEM Needs to Look Like
The answer is not bolting on a separate AI security tool. CTEM itself must evolve.
Discovery needs to expand to include AI-specific probes, AI-focused subdomain enumeration, and passive reconnaissance targeting inference servers, MCP endpoints, vector databases, and AI gateways. Explore our AI Exposure Cheatsheet 🔗 for more ideas.
Profiling needs to go deeper. It is not enough to know that a port is open. CTEM must fingerprint the exact AI software, determine its version, enumerate loaded models, assess authentication posture, and test for known vulnerabilities.
Data awareness must be built in. When a vector database appears in a scan, CTEM should treat it as a high context asset, not just another database.
Agent and tool awareness is critical. A server with a file system and database tools exposed without authentication represents a completely different risk level compared to a standalone inference endpoint.
Risk scoring must reflect context. Severity depends on what the AI system can access, not just whether it is exposed. Model sensitivity, tool power, data proximity, and authentication state must influence prioritization.
The Governance Dimension
AI exposure is not only technical. Regulatory expectations are evolving. Organizations are increasingly expected to know what AI systems they operate and what data those systems process.
An externally visible AI system that security is unaware of is not just a vulnerability. It is a governance failure.
You cannot govern what you cannot inventory. And you cannot inventory what you cannot see from the outside.
An AI Bill of Materials, a continuously updated inventory of externally visible AI systems and their risk posture, is quickly becoming a necessity rather than a forward-looking idea.
How We Are Approaching This at RedHunt Labs
At RedHunt Labs, we have spent years building external attack surface management capabilities designed to uncover what organizations do not know they have exposed. Our CTEM platform 🔗 continuously discovers, profiles, and monitors assets ranging from forgotten subdomains and exposed cloud storage to misconfigured containers and leaked secrets.
AI is the next asset class we are bringing into our platform.
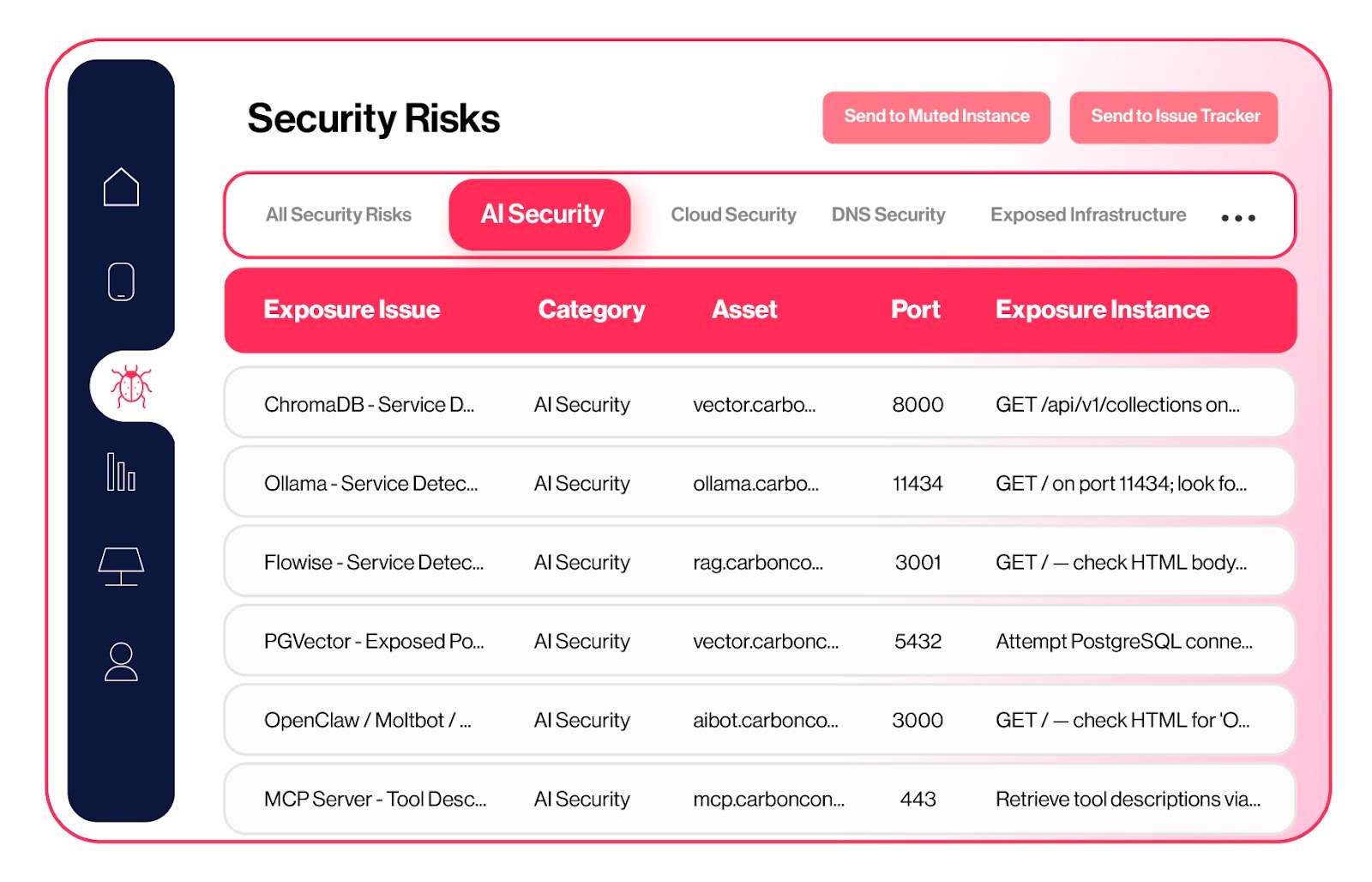
We are integrating AI-aware discovery directly into our scanning pipeline with dedicated probes for inference servers, MCP endpoints, vector databases, AI gateways, MLOps platforms, and agent frameworks. These probes do more than confirm that a service exists. They profile it in depth, identifying the software type, version, loaded models, authentication posture, accessible tools, and connected data layers. We are also building AI-specific risk scoring that reflects context. Exposure is not binary. The real question is what that AI system can access, execute, or influence.
What makes this evolution possible is not a new standalone initiative, but the intelligence foundation we have already built. Through Project Resonance 🔗 and our research initiatives, we have developed internet-scale data collection pipelines and a mature external data lake spanning domains, certificates, repositories, cloud assets, containers, and leaked credentials. Our fingerprinting engines, exposure validation workflows, and contextual scoring mechanisms are already embedded into the platform.
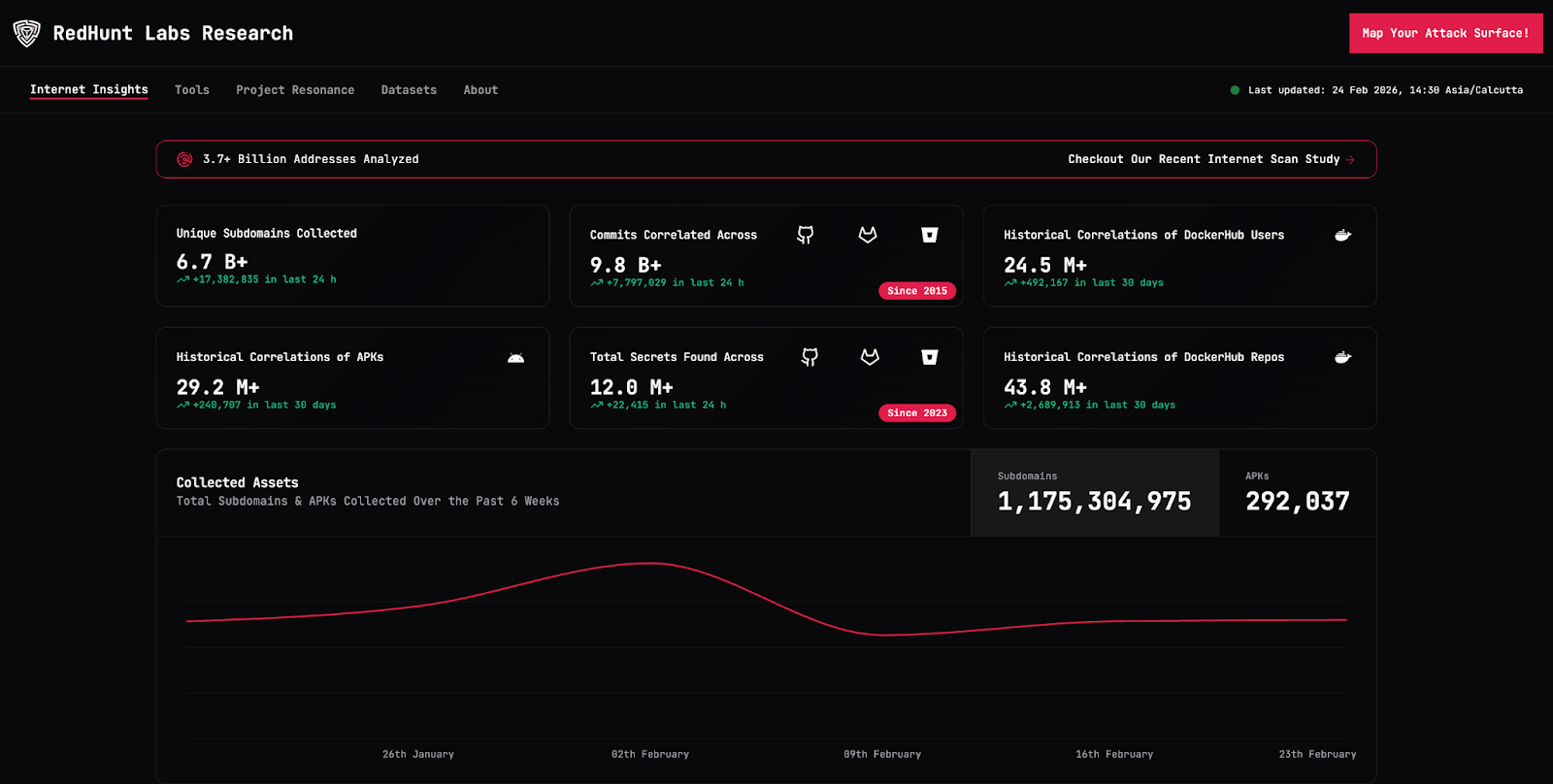
We are not reacting to the trend. We are extending a research-driven external intelligence engine to address the next frontier of exposure risk.
What Comes Next
AI exposure has become a common breach vector. Not because AI is inherently insecure, but because the speed of adoption has outpaced visibility and control.
Insurance underwriters will start asking about AI exposure. Auditors will ask for AI asset inventories. CTEM programs that cannot see AI infrastructure will carry a growing blind spot. It all comes down to this: AI-aware CTEM is no longer a good-to-have; it is a MUST-HAVE. It is the natural evolution of external risk management.
At RedHunt Labs, we are already seeing this play out through our research and external telemetry. The same approach that uncovered exposed cloud assets and leaked credentials is now surfacing AI systems that organizations do not even realize are exposed. If you are starting, exploring, or working in this space too, we would love to exchange notes. Please get in touch with us 🔗
The problem is no longer just discovery. It is understanding what those systems can do. If AI is not visible in your attack surface today, the first time you encounter it may not be during discovery, but during incident response.
.
The real question is simple: Is AI visible in your attack surface program,
or will you discover it during incident response?
.